独家发布在【小专栏】,希望能给买不到票参加大会的朋友带来帮助。
这篇文章是我在 2017 北京【droidcon 大会】技术分享时所讲内容的文字版本,修改删减了演讲时的冗余言语。
仅发布在【小专栏】,和【开源实验室】希望能给买不到票参加大会的朋友带来帮助。
大家好,今天跟大家分享的主题是《优雅移除模块间的耦合》

首先自我介绍一下:我叫张涛,目前是饿了么移动技术部。可能有些朋友认识我,我有一个博客叫【开源实验室】应该或多或少都有听过一些。其他一些虚的东西就不说了,接下来进入今天的主题。

今天我们讲的主题是基于项目模块化来说的,模块化是什么大家肯定都是知道了的,这里问一下大家,有多少人在此之前有做过模块化的,举个手我看一下;了解过听说过模块化的呢?这次比较多。
我们说,做模块化其实跟项目重构很像,都是从这几个点来做的,只是侧重点不同。分别是:删除、组织、降级、解耦。那么这四点是什么意思呢,那么接下来跟大家分享一下我是如何理解这四大块的:
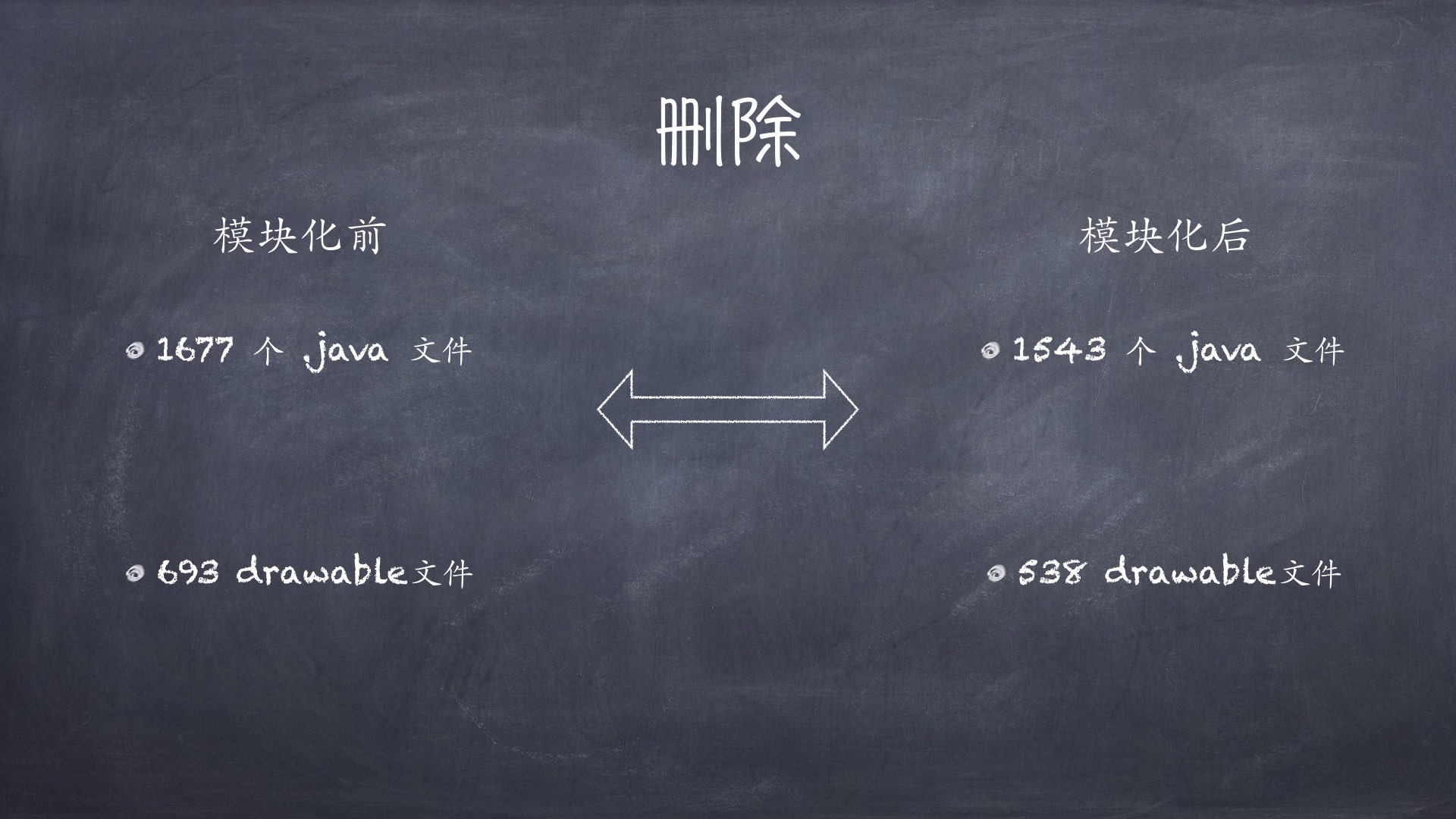
删除:删除不必要的文件,尽可能减小工程体积。这里有一组数据,是我统计我们饿了么的一款 APP 在模块化前后一些文件的数量。
可以看到,.java文件从1677个减少到了1543个。其实这不是重点,重点是下面的drawable,这里drawable只包含图片、和xml布局,当经过模块化重构后文件数从 693 减少到 538 个。图片资源减少接近 200 个,apk 的大小也会随之降低。
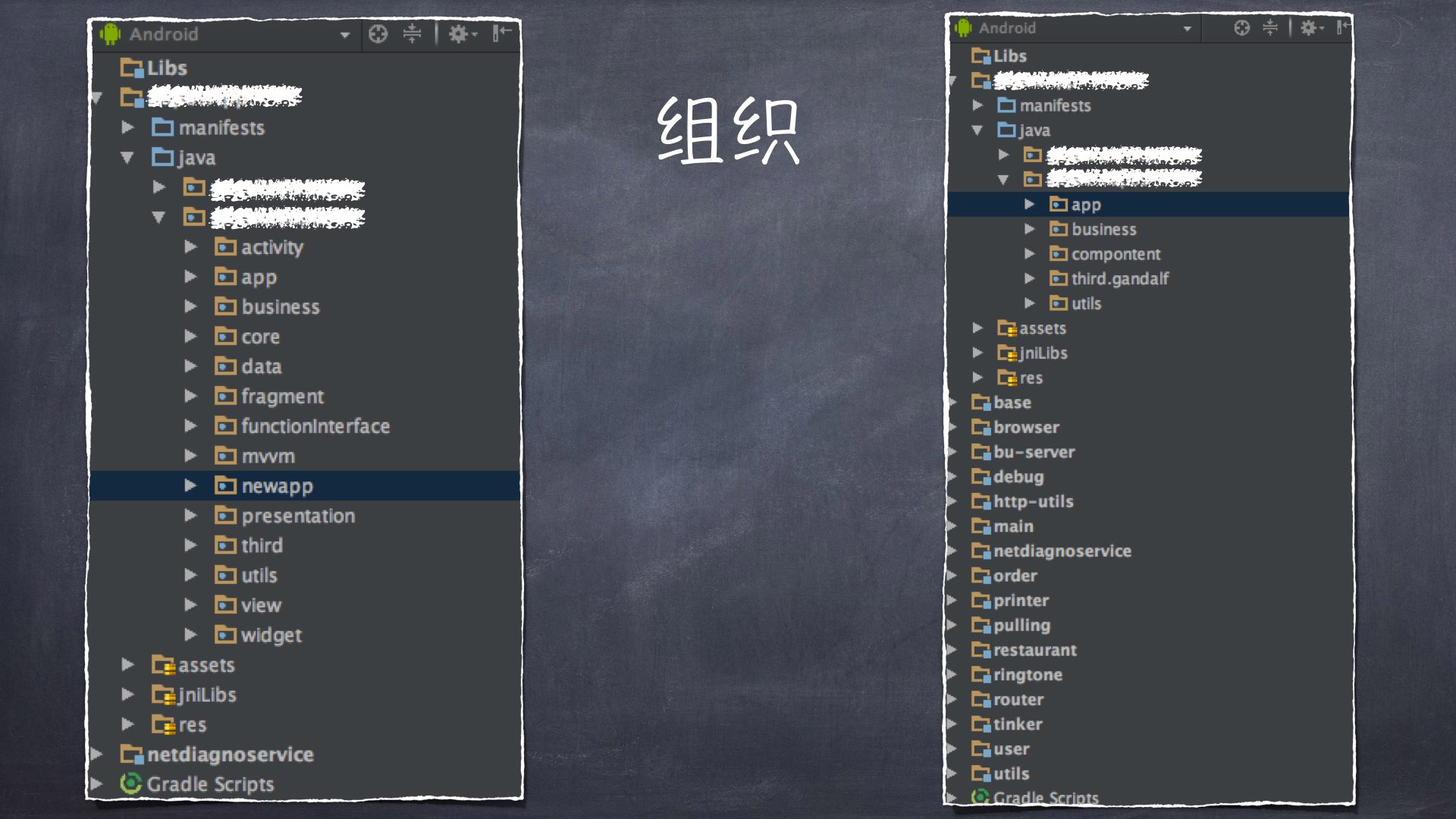
而组织呢,指的是:按照有意义的标准将代码分组。这其实也是java的包所存在的目的之一。
但是随着项目的不断迭代,需求很紧的情况下是很难有时间去真正规范的将类分组的。看到图中,我们之前的结构很乱,就是因为项目快速迭代和人员更替的过程中,不免会有这样的现象。所以这也是模块化重构时所作的一件大事。
接下来就是我们经常说的内聚和耦合了,但是呢内聚不是我们想象的那样的。我不知道大家有没有看过RecyclerView的源码,RecyclerView总共有五个主要的类,分别是:LayoutManager、Adapter、ViewHolder、ItemAnimator、ItemDecoration但是都写在了一个类里面,后来我在某个社交平台上看到有人说这叫高内聚,非常的搞笑。
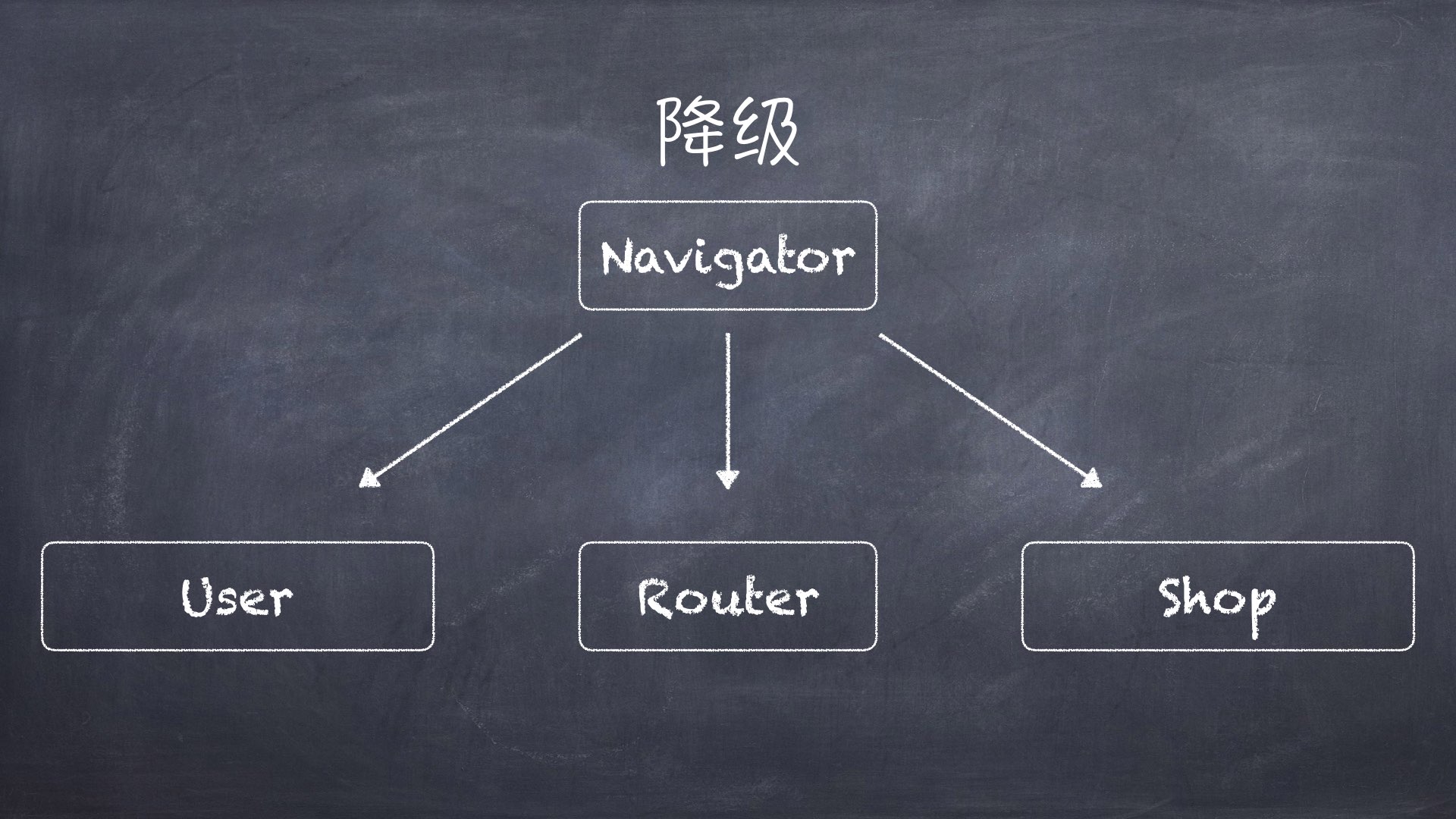
再看回我们项目中的这个例子,降级。很多人也喜欢叫下沉,但其实我认为从项目架构的角度被称为降级更合适。我们之前有一个类叫:Navigator,它是负责几乎所有Activity直接跳转的。就是我们会把所有的startActivity()的跳转放到这个类里面去写。之前少的时候还好,结果等我看到这个类的时候,这个类已经有 200 多个方法了,全是Activity跳转的方法,其中还有重复的,就是很早之前有人写了一个跳到某个界面,结果之后来了个人,他不知道又写一个。
而我们在做模块化重构时的做法就是,首先观察自己的项目,这是重构很重要的一步,就是要结合自身。把这个类拆分成了三大部分,我们有两块业务是会频繁跳转的但这两个业务跳转的页面又都是在自身的模块内,分别是用户模块和商户模块。因此我们将这两个模块中分别建立两个用于模块自己内部的跳转叫UserNavigator和ShopNavigator,而模块间的跳转或一些小模块内部的则使用Router去做,我们自己定义了一个路由库,其实实现跟现在开源的区别不大。

最后解耦,也是今天的重点,如何优雅移除模块间的耦合。 到目前为止,我们已经能够做到让所有不包含业务状态接口的模块的增删,不需要改动任何一行代码。具体到一个示例就是这样:

其本质就是一个模块就是一个功能,你想要让你的 apk 具备这个功能,就添加这个模块一起编译就可以了。这才是我们说的真正的组件化,模块之间零耦合,增减模块零改动。
例如图中:debug这个模块,肯定不会用在正式的生产环境;而相反的tinker这个模块,热补丁肯定也不会用于调试阶段。所以我在开发时就可以不使用这个模块相关的代码。
另外再举个使用的例子:我有一个订单模块,订单模块需要播放铃声,比如大家在饭店经常听到“您有新的饿了么订单,请及时处理”。但我在开发订单模块的时候,如果我已经确定铃声播放是没有问题的,那我可以选择开发阶段不打铃声的包,直到发布到线上了再去加上铃声的包。那我没有添加这个铃声模块的时候,我就默认不具备播放铃声的功能,但完全不影响其他的订单模块的业务功能,而这个铃声模块的增删,是不需要修改任何代码的。
听到这里相信大家都很好奇这是怎么实现的。接下来就跟大家讲讲内部的原理。

所有的核心功能都来自我们自己写的一个库:IronBank。取《自冰与火之歌》中的【铁金库】,叫铁金库不容拖欠。
铁金库的内部实现,其实是使用了 APT 注解处理器,去在编译时解析注解生成一个类,让这个类去生成跨模块的对象。铁金库使用了与 SOA 设计思路类似的方式:将模块之间的主动依赖倒置,变为功能的提供与使用。
那什么是 SOA 的设计思路呢,我们看到一张我画的漫画图:SOA 是一种面向服务的架构模型。

例如图上左边有一个对外提供媒体功能的服务提供者,他告知IronBank我提供媒体服务:“嘿,老铁,我这有个媒体服务,你那边有谁要用的时候可以用我的。”
到了另一边,如果此刻有模块说是,我需要媒体服务:“老铁,你那有没有媒体服务,我这边需要播一个铃声啊!”。
“有的,给你。”
IronBank就会将之前服务提供者提供给他的媒体对象交给服务使用者。

接下来我们来看具体到代码上是如何使用的:首先是作为服务使用方,也就是上一张图右半部分。我们看到传统的做法是首先声明一个接口类型,然后new出接口的实现类给他赋值。
而使用了IronBank的时候,你是不需要关心接口的实现类到底是谁的。这就是IronBank唯一的用处,隐藏实现类,做到彻底的面相接口编程。

之前说过,IronBank将模块之间依赖倒置,由之前的服务提供方被动的接受调用方调用变为,服务方主动提供服务给调用方。
那作为服务提供方需要做些什么事呢,非常简单,你只需要给你的对象提供public static方法,并加上一个@Creator注解,告诉IronBank这是一个创建器方法就可以了,其他任何事情,都不需要考虑。

而相对于繁杂的应用场景,也有对应的解决办法,例如这里的创建器方法是含参数的。看到示例第一个参数是 tag,第二个是 context 。但是你希望调用者在传的时候将Context作为第一个参数,tag作为第二个参数。

那你在声明的时候就需要显示的声明参数就是这样,加一个 params,然后写上你希望的参数顺序。
这个@Creator注解里面还有很多参数,比如这里返回的是IMedia类型的对象,那如果IMedia接口还继承了一个A接口,这里我虽然返回的是IMedia但我不想外部知道,我就想外部知道我返回的只是个A,这样也是可以显示的在注解参数中声明就行了。
以及还有方法的类所在文件自定义等等等等…… 就不一一列举了。

前面讲IronBank实现完美实现了模块间的解耦,而IronBank的内部实现就是通过这个APT来完成的。Annotation Processing Tool,相信大家都有听说过这个APT,即便是你没听说过,你也肯定早就用过了,只是你不知道。
Android上有一个著名的注解绑定框架叫butterknife,他的内部实现就是通过 APT 来做的,还有Google出品的databinding、dagger2,这些也都是 APT 来做的。那这个注解处理器在IronBank中做了些什么呢,我们来看这段代码。

这是IronBank在编译以后生成的一段类:还是继续我们前面讲的那段示例来继续,在运行时,他会根据你传入的get()方法的参数,来判断你所需要的是哪个接口的实现,然后去调用对应的创建器方法。

在使用上,为了接入方使用方便,我们也对IronBank做了非常多的体验优化。
我们通过自定义lint来使 IDE 可以检查参数类型是否正确。比如前面我们举的例子,如果声明的时候是第一个参数是String第二个参数是Context,那如果你传错了,IDE 直接就报红了。
还有前面我们看到了,IronBank提供了一种类似依赖注入的方式去创建对象,那既然是类似依赖注入一定会碰上循环引用问题。我们自定义的Lint也完美通关静态代码分析在编译期避免了这个问题。
同时在开发的时候还提供了一个Android Studio IDE插件,可以用来帮你把参数智能补全,自动生成代码。前面看到,在写IronBank.get()方法的时候得写很多字,如果有智能补全会少写很多。

紧接着是IronBank的功能,前面我们说了IronBank的唯一功能就是生成对象。
但基于这一个功能,又可以延伸出另外两个能力,就是对象的缓存和单例对象创建。具体到实际代码中来说就是,前面我调用了创建器来创建对象,但如果每次都去调用创建器,而创建器内部都是new出来的对象,这肯定不是一个最好的选择。
以及单例,我们允许你给生成类的声明加一个注解@Single,就默认生成的是单例对象。

在IronBank内部,通过二级缓存来讲已创建过对象的复用。第一级缓存是一个默认容量为 10 的 LRU 队列;第二级缓存是采用软引用的 Map。在一级缓存没有命中时,会在二级缓存中查找。如果二级缓存命中,则将对象放回一级缓存。
讲到这里,整个模块化解耦的全部能力就跟大家介绍完了。最后我们再从宏观角度去看一下整个项目工程的结构,分为三级,最上层是业务模块,紧接着是一些可选的功能组件,最底层则是与项目无关的公共依赖。
今天在这里,跟大家分享了一种我们项目中使用的解耦设计思路,以后大家在做,或者即将开始做模块化的朋友,可以尝试一下这种设计,你会发现非常非常的有效果。
最后,跟大家简单介绍一下模块化中的一些坑,以及处理的办法,对以后大家在碰上这样的问题时也可以有所帮助。 第一个module过多,造成的编译慢的问题。最长的一次达到了9分钟。当然大家可能会觉得9分钟不算长,但我们项目在模块化拆分之前单模块的时候最长也只需要4分钟。后来我们查出来实际上花时间的地方是两个,一个是APT的注解处理,他每个模块都会走一遍,模块越多花费的时间越长。而我们的项目又是大量使用了APT,整个算下来大约延长了一分多钟;另一个就是AOP,我们使用的是字节码处理的也会造成大量的处理耗时。那应对的办法只能是尽量的避免这两个task,比如AOP那我在调试的时候如果不是非要看某些数据,就干脆不走AOP。
还有像自定义Lint,这个在Lint的gradle依赖版本的23.3.3之前,是不支持kotlin代码的。一直到23.3.3才出现了一个叫Detector.UASTScanner的类,这个类是基于抽象语法树来分析的,这才解决这个问题。
还有开发Android Studio插件的时候,如果你要对代码做写操作,必须把写的步骤放到他一个指定的线程里面去做,这样才能生效。而这些资料在网上根本找不到连官方文档都只有提及没有详细说明,我也是问了很多人,查了很多的文档才找到的。

本次分享就到这里,感谢各位。